The Scale Problem: Wikimedia Traffic Analysis
The Narrative:
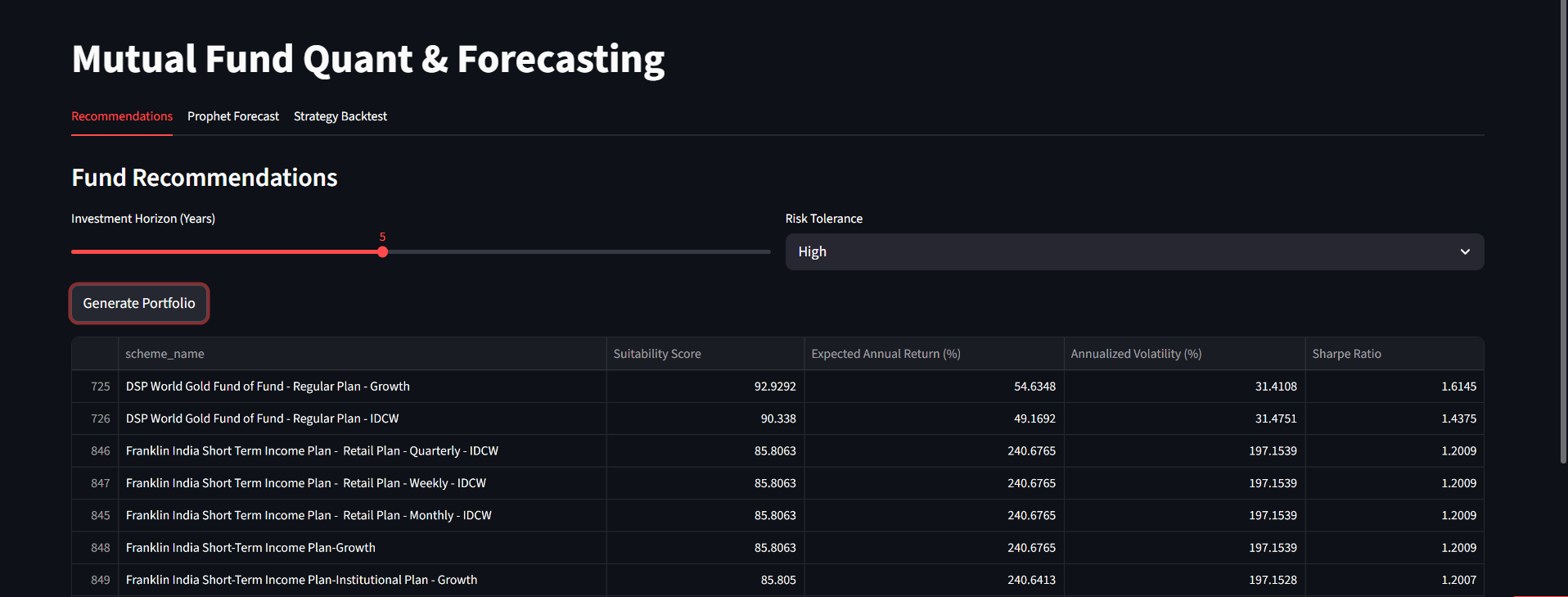
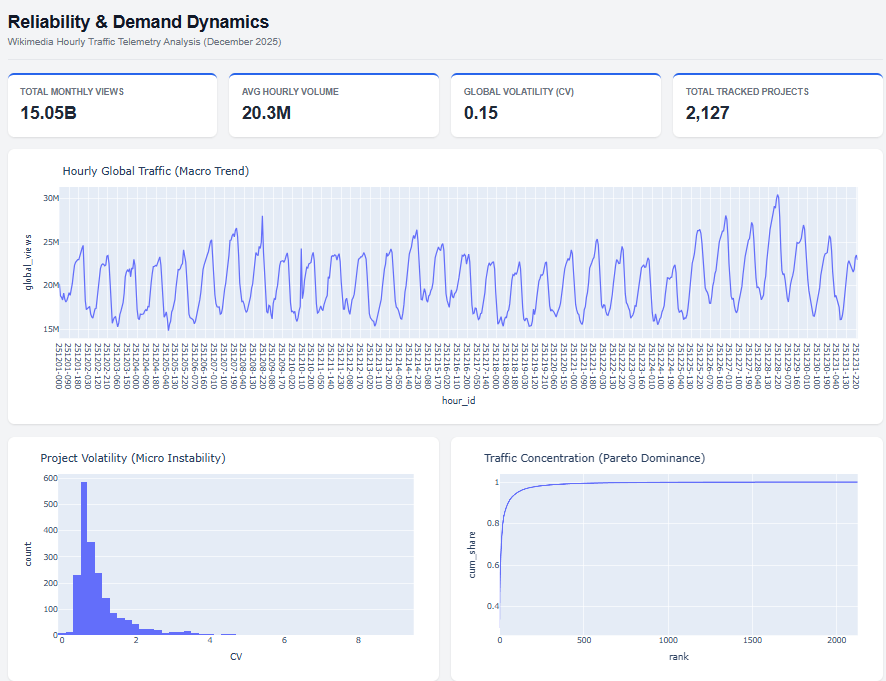
As an analyst, I was accustomed to opening datasets in Pandas and running `.describe()`. But what happens when the dataset is 41GB of raw compressed logs representing over 15 Billion pageviews? Standard tools crashed. Memory overflowed.
I took it upon myself to learn data engineering concepts to solve this analytical bottleneck. Instead of relying on expensive cloud compute, I explored columnar storage and vectorized engines.
The Outcome & Accountability
I implemented DuckDB and a custom partitioning strategy. I capped memory limits ensuring the system wouldn't crash the host machine. The result? Queries that previously failed due to OOM errors now executed in under 850 milliseconds. This project taught me that a good Data Scientist must first be a capable Data Engineer.
df = pd.read_csv('15B_logs.csv') # MemoryError
conn.execute("""
SELECT project, sum(views)
FROM read_parquet('partitioned_logs/**/*.parquet')
GROUP BY project
ORDER BY sum(views) DESC
""")